
In our previous blog titled, “Beginner’s guide to object detection AI”, we introduced the basics of AI, Computer Vision, Object Detection and Object Detection Metrics. In this blog, we explain how Zabble uses these metrics to develop, test and evaluate our AI systems.
In 2024, we released two iterations of this model, each imposing upon the last. The first, released in August, increased accuracy by 5%. The latest, released in October, expanded detection from 10 to 17 items and improved accuracy by 10.5% on overlapping classes.
What exactly do we mean by overlapping classes? Well, we can’t really assess the old model’s ability to detect classes it was never trained on, so we compare accuracy on the shared classes. This means that the newest model can now detect more contamination items while being even better at the ones it is already used to. To see how good this newest object detection model is, we will walk you through the standard metrics used by major AI technologies that incorporate object detection.
Zabble’s Latest Object Detection Metrics
Since there is no benchmark that is available for object detection in waste management we evaluate our models using the standard object detection metric- Mean Average Precision (mAP). For our purposes, we may refer to mAP and accuracy interchangeably. An IoU threshold of 0.5 or 50% is used, which we refer to as mAP50. The threshold can also be increased, depending on the needs of the application. In object detection, you will often see both mAP50 and mAP50-95. The mAP50-95 is the average of all mAP calculations across IoU thresholds ranging from 0.5 to 0.95 in increments of 0.05.
The one you should use largely depends on your goals. At Zabble, we prioritize object presence so we choose to use mAP50 while using mAP50-95 as a comparison metric against other models.
We compare our results to YOLOv8's (one of the state-of-the-art object detection models) performance on Open Images V7 (using mAP50-95) to assess our standing against top benchmarks.

The different YOLO models vary in their computational requirements, affecting how efficiently they run on different devices. For mobile devices, YOLOv8n and YOLOv8s are the most viable options.
When comparing efficiency, YOLOv8s runs at 90.5% the efficiency of Zabble’s new model, while Zabble’s new model operates at 82.64% the efficiency of YOLOv8X (the largest model of the YOLOv8 family). Although YOLOv8X can run on mobile devices, it must be compressed, which reduces accuracy.
However, raw efficiency isn’t the full story. A waste management dataset is likely more complex than this benchmark dataset. Open Images V7 also has approximately 8 million images, whereas Zabble’s dataset consisted of only 14,000 images for the entire process. Hence, this becomes a difficult comparison, and we wish there were a standardized object detection benchmark for waste management, but this provides some insight into where Zabble’s object detection models stand.
To accurately evaluate our model's performance, we employed a stratified split to divide our data into training, validation, and testing sets that each split maintains a similar class distribution. This statistically sound approach prevents biased metric results and ensures that our model's performance evaluation reflects real-world scenarios. Our final data composition resulted in the following:
- Training: 11,210 images (97,674 items)
- Validation: 1,476 images (12,179 items)
- Test: 2,083 images (17,156 items)
Now, you may be wondering what the validation and testing sets are for. The model uses its training data to measure how far its predictions are from the ground truth and then adjusts its internal parameters to minimize this error as much as possible.
There are instances where a model becomes too good at predicting the training data but fails when deployed in real-world scenarios with unseen data. This is where the validation set helps during training as it serves as a gauge of how well the model is expected to perform outside of training. If the mAP50 score increases for both the training and validation sets over each iteration, the model is generalizing well. However, if the mAP50 increases for the training set but starts decreasing for the validation set, it indicates overfitting. Preventative measures should be taken to ensure the model does not memorize training data at the expense of real-world performance.
The final model is selected based on the highest mAP50 score on the validation data, by optimizing various hyperparameters during training to improve performance. This selection process can, however, introduce bias toward the validation data, necessitating a separate test set for an unbiased evaluation.
The mAP50 score on the test set, which is the final measure of model performance in the real world, is not calculated until the model has been fully trained and optimized based on the validation set. This concept is often overlooked in AI vision systems, where metrics are frequently reported based on the validation set. This approach may be acceptable for smaller datasets, but this makes real-world evaluations of such vision systems overoptimistic, at best.
At Zabble, we aim to ensure that the metrics we present are the most reliable indicators of how our models perform in real-world conditions. Overall, Zabble’s new AI model achieves an mAP50 of 54.5 on the test set, reflecting a 10.5% improvement in overlapping classes compared to its predecessor. This positions it as a well-performing model for contamination identification.
Below is a more detailed breakdown of how the model performs at a per-class level:
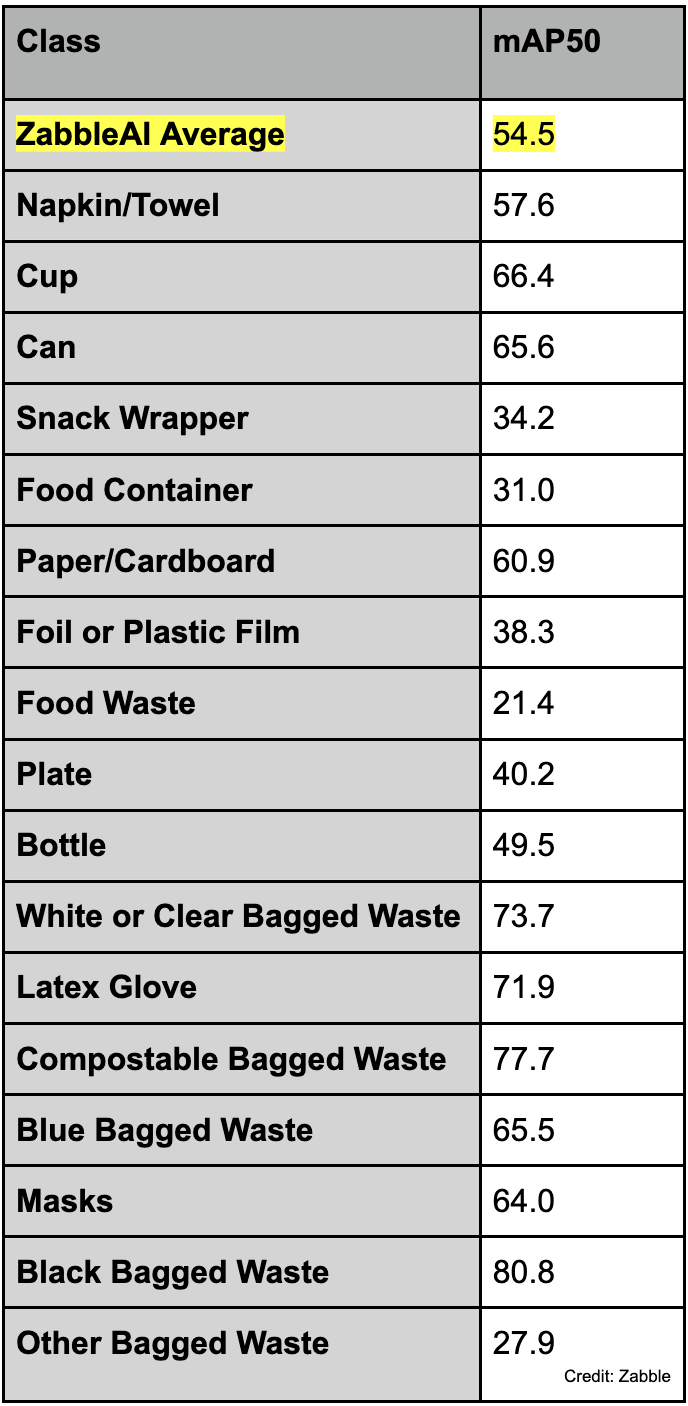
Conclusion
To conclude, our newest object detection model improves upon previous iterations with the ability to detect 7 new classes (17 in total), while maintaining performance comparable to state-of-the-art models. Generally, an mAP50 of 50 or higher indicates good performance and ZabbleAI scored an average score of 54.5.
The work does not stop here! This is just the beginning. We continuously refine these detection models, analyzing where they succeed and where they fall short, to drive ongoing improvements and enhance Zabble’s customer experience.
Thank you for reading!
If you want to know more about how Zabble applies these AI models to detect contamination through our mobile application, please reach out to us for a live demo.
Our Latest Blog Posts
Zero Waste
Zabble Wants to Play with Your Garbage
This blog post discusses Zabble's team visits to key partners, PSSI, Stanford and UCSF, to observe a day in their lives and how they use Zabble's products for zero waste initiatives. At PSSI, Zabble's team rode along with garbage and recycling truck drivers, observing challenges like route changes and contamination. They learned about the importance of real-time communication and notifications for addressing these issues. At UCSF, the team witnessed manual waste sorting and the need for technology that works offline. They also saw how Zabble's "Alerts" feature helps communicate contamination and hazardous items. The blog concludes with the value of these visits and the vision for Zabble 3.0, which aims to provide more granular insights and proactive engagement for achieving zero waste.
Wednesday, April 23, 2025
Artificial Intelligence
How Zabble's Object Detection Model Stacks Up Against Industry Benchmarks
A summary of Zabble's AI object detection models development process and how we use industry metrics and benchmarks to develop, test and evaluate our AI systems.
Wednesday, April 2, 2025
Artificial Intelligence
A Beginner’s Guide to Object Detection AI
Read about the basics of object detection AI, challenges to developing a methodology and metrics and what it means for contamination detection and identification at the bin.
Monday, March 31, 2025
ADDRESS
1966 Tice Valley Blvd, #105,
Walnut Creek, CA 94595
CONTACT
Tel.: 925-289-9345
Email: team@zabbleinc.com

Mobile Tagging
U.S. Patent No. 11,788,877
Social Icons
